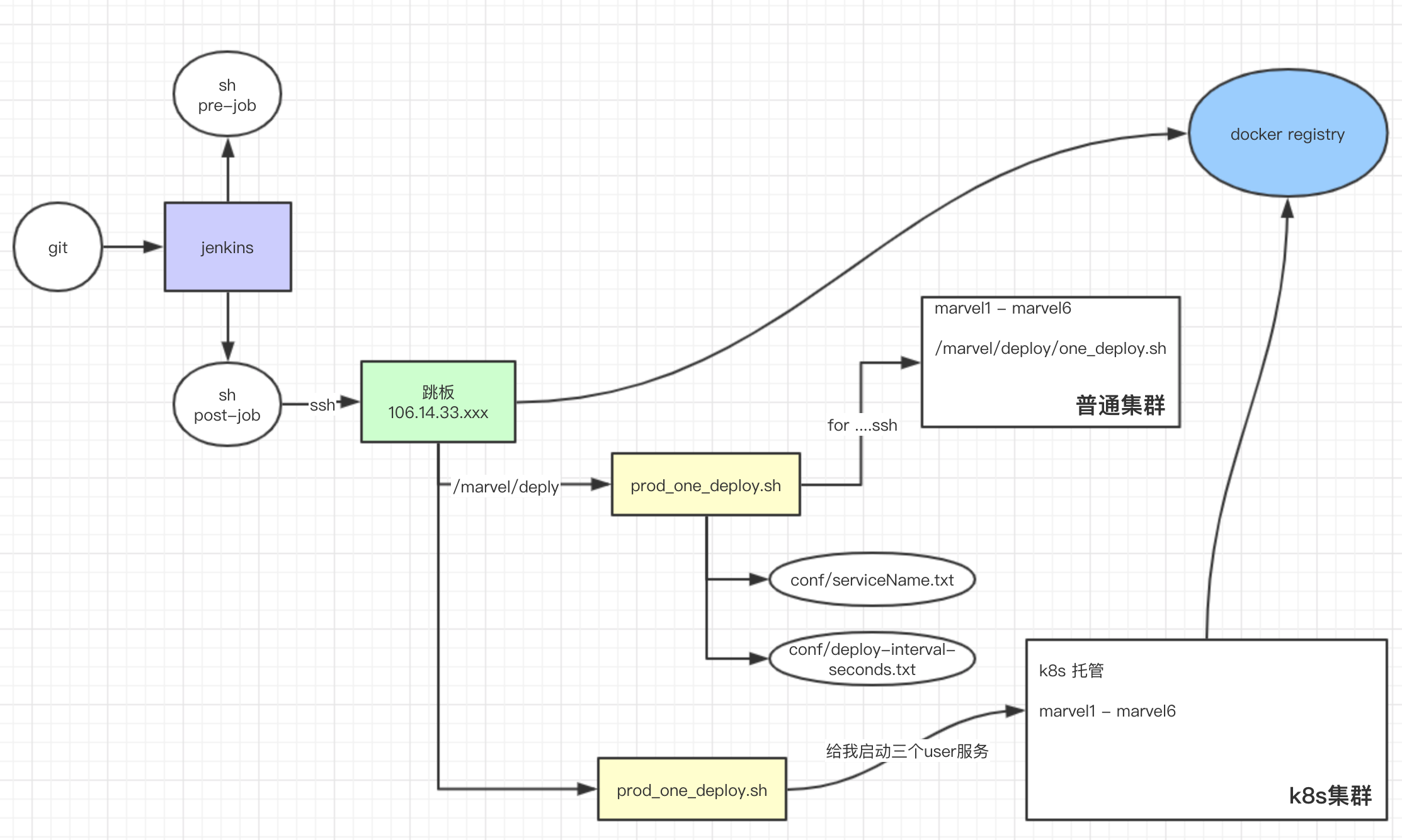
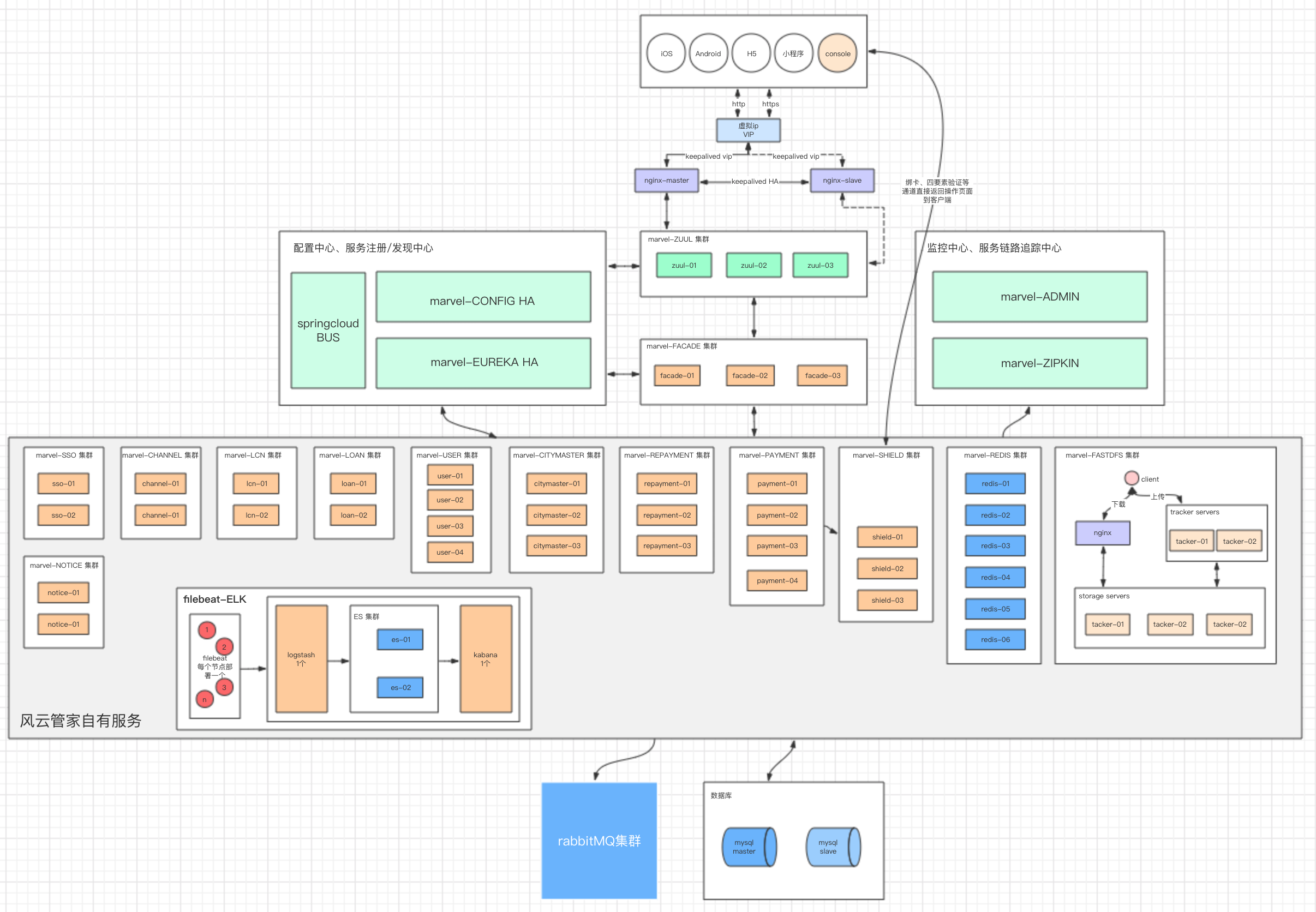
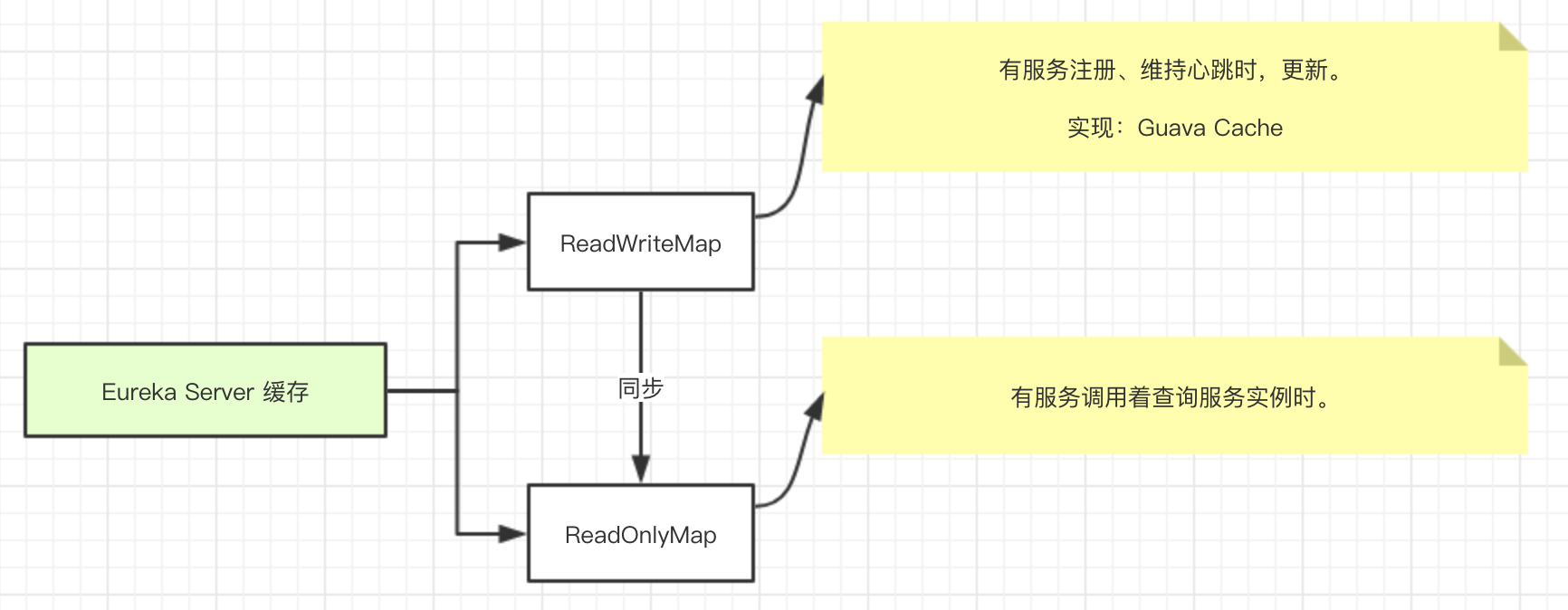
1 | 2019-06-24 14:18:36.810 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/archaius],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
2 | 2019-06-24 14:18:36.811 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/auditevents],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
3 | 2019-06-24 14:18:36.811 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/beans],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
4 | 2019-06-24 14:18:36.812 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/health],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
5 | 2019-06-24 14:18:36.812 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/conditions],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
6 | 2019-06-24 14:18:36.812 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/configprops],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
7 | 2019-06-24 14:18:36.812 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/env],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
8 | 2019-06-24 14:18:36.813 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/env/{toMatch}],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
9 | 2019-06-24 14:18:36.813 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/env],methods=[POST],consumes=[application/vnd.spring-boot.actuator.v2+json || application/json],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
10 | 2019-06-24 14:18:36.814 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/env],methods=[DELETE],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
11 | 2019-06-24 14:18:36.814 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/info],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
12 | 2019-06-24 14:18:36.814 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/logfile],methods=[GET],produces=[application/octet-stream]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
13 | 2019-06-24 14:18:36.814 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/loggers],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
14 | 2019-06-24 14:18:36.815 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/loggers/{name}],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
15 | 2019-06-24 14:18:36.815 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/loggers/{name}],methods=[POST],consumes=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
16 | 2019-06-24 14:18:36.815 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/heapdump],methods=[GET],produces=[application/octet-stream]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
17 | 2019-06-24 14:18:36.815 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/threaddump],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
18 | 2019-06-24 14:18:36.816 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/metrics/{requiredMetricName}],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
19 | 2019-06-24 14:18:36.816 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/metrics],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
20 | 2019-06-24 14:18:36.816 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/scheduledtasks],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
21 | 2019-06-24 14:18:36.817 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/httptrace],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
22 | 2019-06-24 14:18:36.817 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/mappings],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
23 | 2019-06-24 14:18:36.817 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/refresh],methods=[POST],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
24 | 2019-06-24 14:18:36.817 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/features],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
25 | 2019-06-24 14:18:36.818 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/service-registry],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
26 | 2019-06-24 14:18:36.818 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator/service-registry],methods=[POST],consumes=[application/vnd.spring-boot.actuator.v2+json || application/json],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto public java.lang.Object org.springframework.boot.actuate.endpoint.web.servlet.AbstractWebMvcEndpointHandlerMapping$OperationHandler.handle(javax.servlet.http.HttpServletRequest,java.util.Map<java.lang.String, java.lang.String>) |
27 | 2019-06-24 14:18:36.819 [main] INFO o.s.b.a.e.w.s.WebMvcEndpointHandlerMapping - 547 : Mapped "{[/actuator],methods=[GET],produces=[application/vnd.spring-boot.actuator.v2+json || application/json]}" onto protected java.util.Map<java.lang.String, java.util.Map<java.lang.String, org.springframework.boot.actuate.endpoint.web.Link>> org.springframework.boot.actuate.endpoint.web.servlet.WebMvcEndpointHandlerMapping.links(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse) |